

Back in 2013, I published an unattended installation script for Exchange Server 2013, together with a walkthrough on this blog. At the time, the goal was simple: make Exchange deployments more predictable, repeatable, and less error‑prone by removing as much manual interaction as possible.
Exchange has evolved, deployment practices have matured, and automation expectations are much higher. Over the past years, I have continued to maintain and refine the script to keep pace with those changes. Recently, I completed a major cleanup and refresh. Those watching my GitHub have likely seen the incremental changes.
This post serves as a refresher and high‑level overview on the current state.
Goal
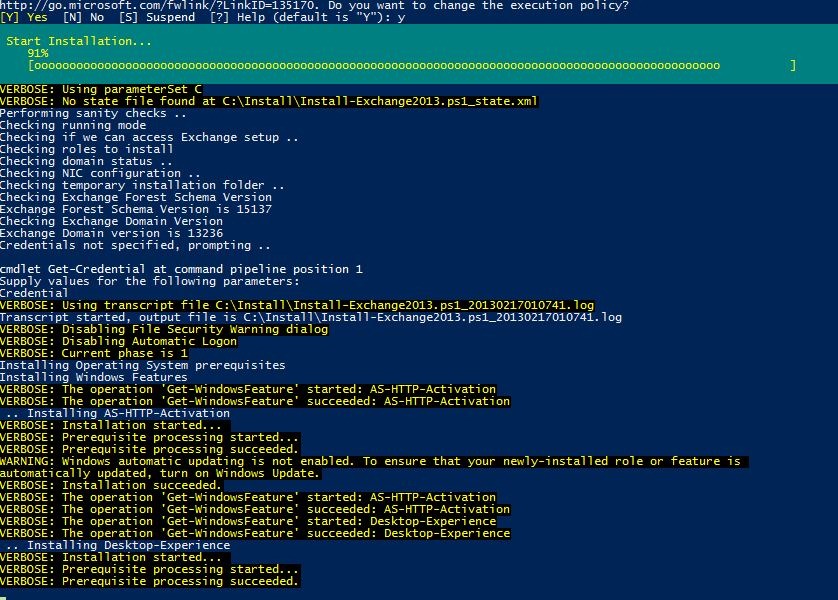
This script automates the unattended installation of Microsoft Exchange Server 2016, 2019, and Exchange Server SE on Windows Server 2016 through 2025. For this, it follows a state machine process. This is necessary because some steps require a reboot before continuing.

The script handles the full installation lifecycle: Windows features, prerequisites (.NET, VC++ runtimes, IIS components), Active Directory preparation, Exchange setup, and post-configuration and hardening. With the -AutoPilot switch, the script manages automatic reboots and logon cycles, tracking progress in a JSON state file to track where it is in the process.
Supported Builds and Operating Systems
| Exchange Version | Minimum OS | Maximum OS |
|---|---|---|
| Exchange 2016 CU23 | Windows Server 2016 | Windows Server 2019 |
| Exchange 2019 CU10–CU14 | Windows Server 2019 | Windows Server 2022 |
| Exchange 2019 CU15 | Windows Server 2019 | Windows Server 2025 |
| Exchange Server SE RTM | Windows Server 2019 | Windows Server 2025 |
For Exchange 2019 and up, deployment on Desktop or Core is supported. Support for Exchange 2013, older CUs for Exchange 2016 and Exchange 2019, and older operating systems (WS2008, WS2008 R2, WS2012, or WS2012 R2) has been removed since version 4.0 of the script.
Requirements
- PowerShell 5.1 or later
- Domain-joined system (Edge Server role is the exception)
- An account with local administrator rights
- When using
-AutoPilot: the account must be able to configure and perform auto-logon - When creating a new Exchange organization (
-Organization) or need to upgrade schema or domain configuration: Schema Admin and Enterprise Admin rights - Static IP address (running as an Azure VM is the exception)
Usage
The syntax for calling the script depends on which of the common scenarios you want to deploy. By default, it is to perform an installation:
Install-Exchange15.ps1 [-Organization] [-MDBName ] [-MDBDBPath ] [-MDBLogPath ] [-InstallPath ] [-SourcePath ] [-TargetPath ] [-AutoPilot] [-Credentials ] [-IncludeFixes] [-NoNet481] [-DoNotEnableEP] [-DoNotEnableEP_FEEWS] [-DisableSSL3] [-DisableRC4] [-EnableECC] [-NoCBC] [-EnableAMSI] [-DisableTLS10] [-DisableTLS11] [-DisableInsecureRenegotiation] [-DisableWeakCiphers] [-DisableWeakHashAlgorithms] [-DisableNonForwardSecretKeyExchange] [-DisableCredentialGuard] [-EnableTLS12] [-EnableTLS13] [-SCP ] [-DiagnosticData] [-Lock] [-SkipRolesCheck]
You can use it to install an Edge Transport server:
Install-Exchange15.ps1 -InstallEdge -EdgeDNSSuffix [-InstallPath ] [-SourcePath ] [-AutoPilot] [-Credentials ] [-IncludeFixes] [-NoNet481] [-DoNotEnableEP] [-DoNotEnableEP_FEEWS] [-DisableSSL3] [-DisableRC4] [-EnableECC] [-NoCBC] [-EnableAMSI] [-DisableTLS10] [-DisableTLS11] [-DisableInsecureRenegotiation] [-DisableWeakCiphers] [-DisableWeakHashAlgorithms] [-DisableNonForwardSecretKeyExchange] [-DisableCredentialGuard] [-EnableTLS12] [-EnableTLS13] [-DiagnosticData] [-Lock] [-SkipRolesCheck]
Or you can use it for recovery:
Install-Exchange15.ps1 -Recover [-InstallPath ] [-SourcePath ] [-AutoPilot] [-Credentials ] [-IncludeFixes] [-NoNet481] [-DoNotEnableEP] [-DoNotEnableEP_FEEWS] [-DisableSSL3] [-DisableRC4] [-EnableECC] [-NoCBC] [-EnableAMSI] [-DisableTLS10] [-DisableTLS11] [-DisableInsecureRenegotiation] [-DisableWeakCiphers] [-DisableWeakHashAlgorithms] [-DisableNonForwardSecretKeyExchange] [-DisableCredentialGuard] [-EnableTLS12] [-EnableTLS13] [-DiagnosticData] [-Lock] [-SkipRolesCheck]
The script Install-Exchange15.ps1 has a ton of options. An explanation of these is given in the table below. Depending on the operating mode (regular setup, preparation only, Edge Transport installation, or recovery), parameters may or may not become available.
| Parameter | Description |
|---|---|
-SourcePath | Path to Exchange setup EXE folder or ISO file |
-Organization | Exchange organization name to create. Omit to skip AD preparation. |
-InstallEdge | Install the Edge Transport server role instead of Mailbox |
-AutoPilot | Fully automated mode — handles reboots and resumes automatically |
-Credentials | Credentials AutoPilot uses for automatic logon after each reboot |
-InstallPath | Working folder for state file, logs, and downloaded prerequisites (default: C:\Install) |
-MDBName | Name of the initial mailbox database |
-MDBDBPath | Path for the mailbox database file |
-MDBLogPath | Path for the mailbox database transaction logs |
-TargetPath | Exchange binaries installation path (default: C:\Program Files\Microsoft\Exchange Server\V15) |
-SCP | Autodiscover Service Connection Point URL to set after installation. Use - to clear. |
-IncludeFixes | Install additional recommended hotfixes and security updates |
-DisableSSL3 | Disable SSL 3.0 |
-DisableRC4 | Disable the RC4 cipher suite |
-EnableECC | Configure Elliptic Curve Cryptography |
-EnableTLS12 | Configure TLS 1.2 |
-EnableTLS13 | Configure TLS 1.3 (WS2022/WS2025 with Exchange 2019 CU15+) |
-EnableAMSI | Enable AMSI body scanning for ECP, EWS, OWA, and PowerShell virtual directories |
-DisableTLS10 | Disable TLS 1.0 |
-DisableTLS11 | Disable TLS 1.1 |
-DisableInsecureRenegotiation | Disallow insecure TLS renegotiation (AllowInsecureRenegoClients and AllowInsecureRenegoServers set to 0) |
-DisableWeakCiphers | Disable weak SCHANNEL ciphers: NULL, DES 56/56, RC4 40/128, RC4 56/128, RC4 64/128, RC4 128/128, Triple DES 168 |
-DisableWeakHashAlgorithms | Disable weak SCHANNEL hash algorithms: MD5 and SHA-1 |
-DisableNonForwardSecretKeyExchange | Disable non-forward-secret key exchange (PKCS/static RSA) |
-DisableCredentialGuard | Disable Credential Guard (LsaCfgFlags and EnableVirtualizationBasedSecurity set to 0) |
-NoSetup | Install prerequisites only; skip Exchange setup |
-Recover | Run in RecoverServer mode |
-NoNet481 | Use .NET 4.8 instead of 4.8.1 |
-DoNotEnableEP | Skip enabling Extended Protection (Exchange 2019 CU14+) |
-Lock | Lock the workstation screen during installation |
-DiagnosticData | Set the initial diagnostic data collection mode |
Because of the number of parameters, you might want to use splatting when calling the script, for example:
$Cred = Get-Credential
$Params = @{
Organization = 'Fabrikam'
SourcePath = '\\server\iso\ExchangeServer2019-x64-CU15.iso'
InstallPath = 'C:\Install'
Credentials = $Cred
MDBName = 'MDB1'
MDBDBPath = 'C:\MailboxData\MDB1\DB'
MDBLogPath = 'C:\MailboxData\MDB1\Log'
SCP = 'https://autodiscover.fabrikam.com/autodiscover/autodiscover.xml'
AutoPilot = $true
DisableSSL3 = $true
DisableRC4 = $true
DisableTLS10 = $true
DisableTLS11 = $true
DisableInsecureRenegotiation = $true
DisableWeakCiphers = $true
DisableWeakHashAlgorithms = $true
DisableNonForwardSecretKeyExchange = $true
EnableTLS12 = $true
EnableECC = $true
EnableAMSI = $true
Verbose = $true
}
.\Install-Exchange15.ps1 @Params
More information
More information and recent documentation updates will be published on GitHub, including instructions in the README and changes in CHANGELOG.MD.
Download
The script is available from GitHub.
References
This post replaces the previous articles on the installation script, which are still there for historical purposes (and to show what has been updated or replaced over time):
 A short blog on a small survey I’ve been running for some time now on the usage of
A short blog on a small survey I’ve been running for some time now on the usage of 





